Environment Quick Summary#
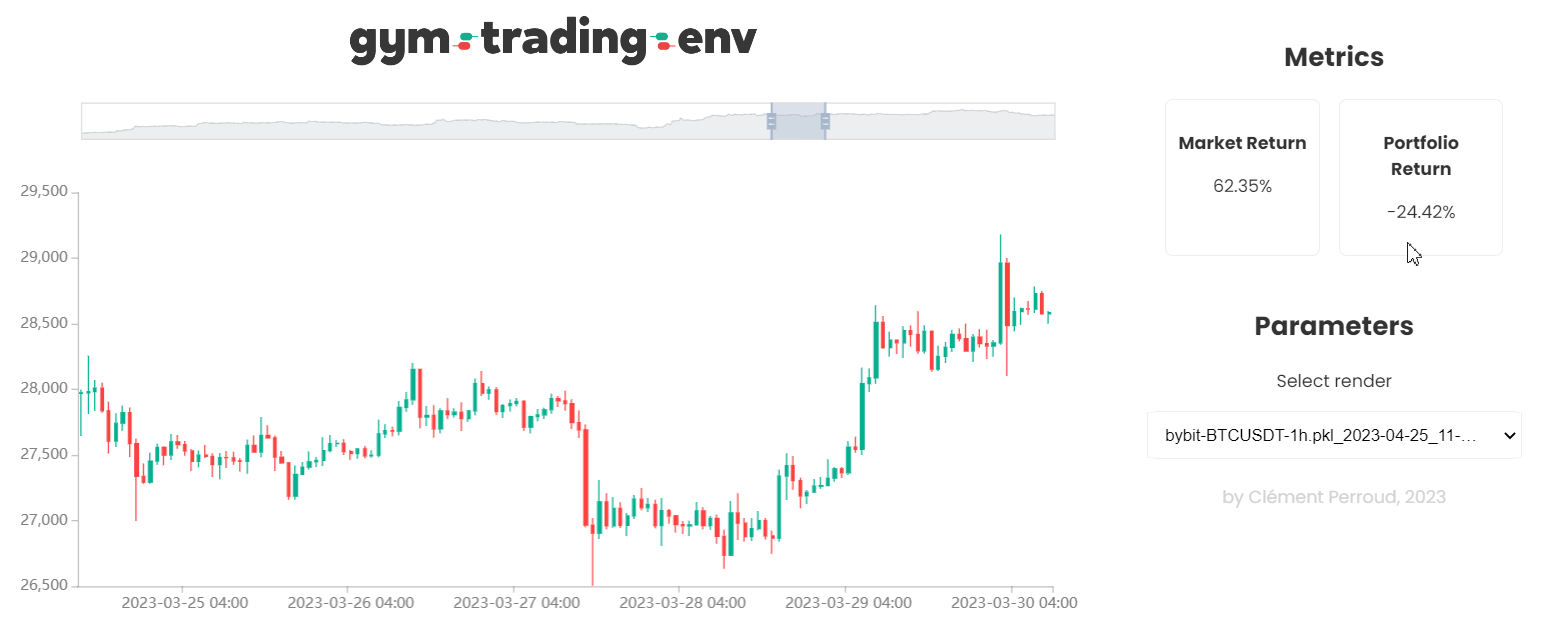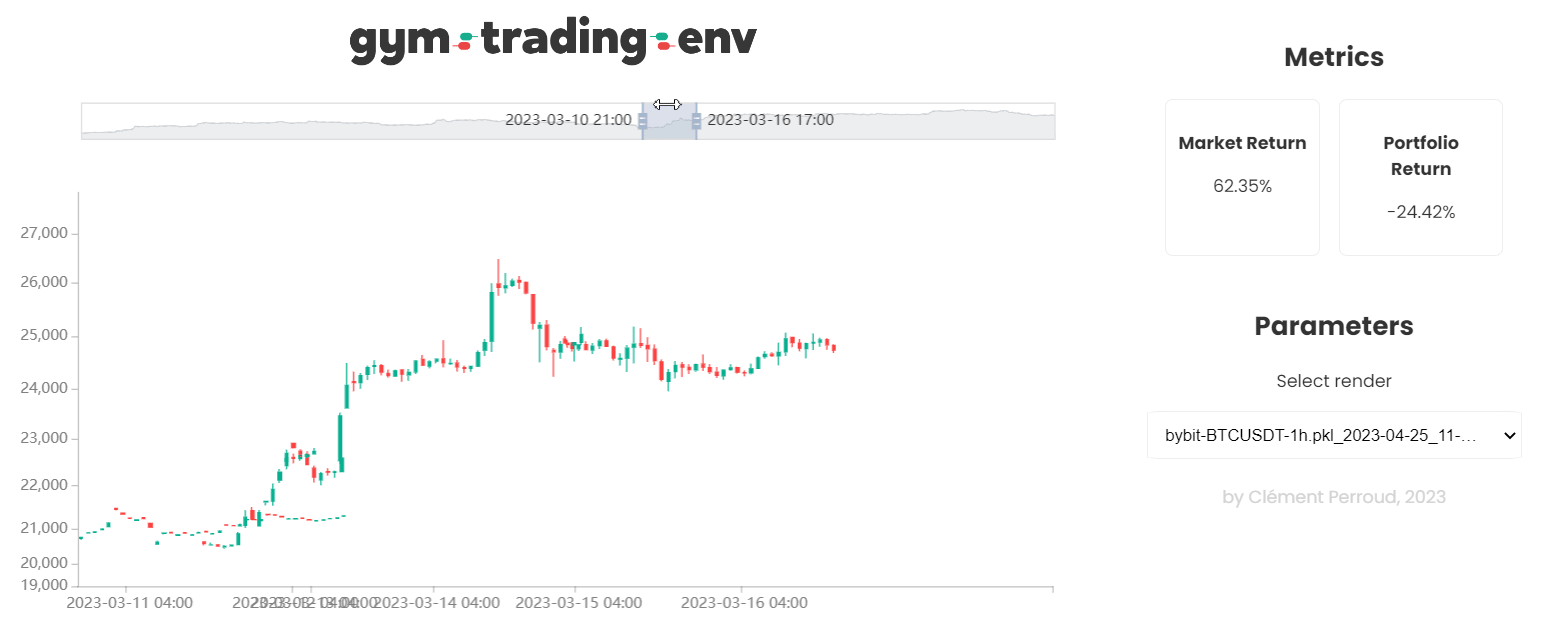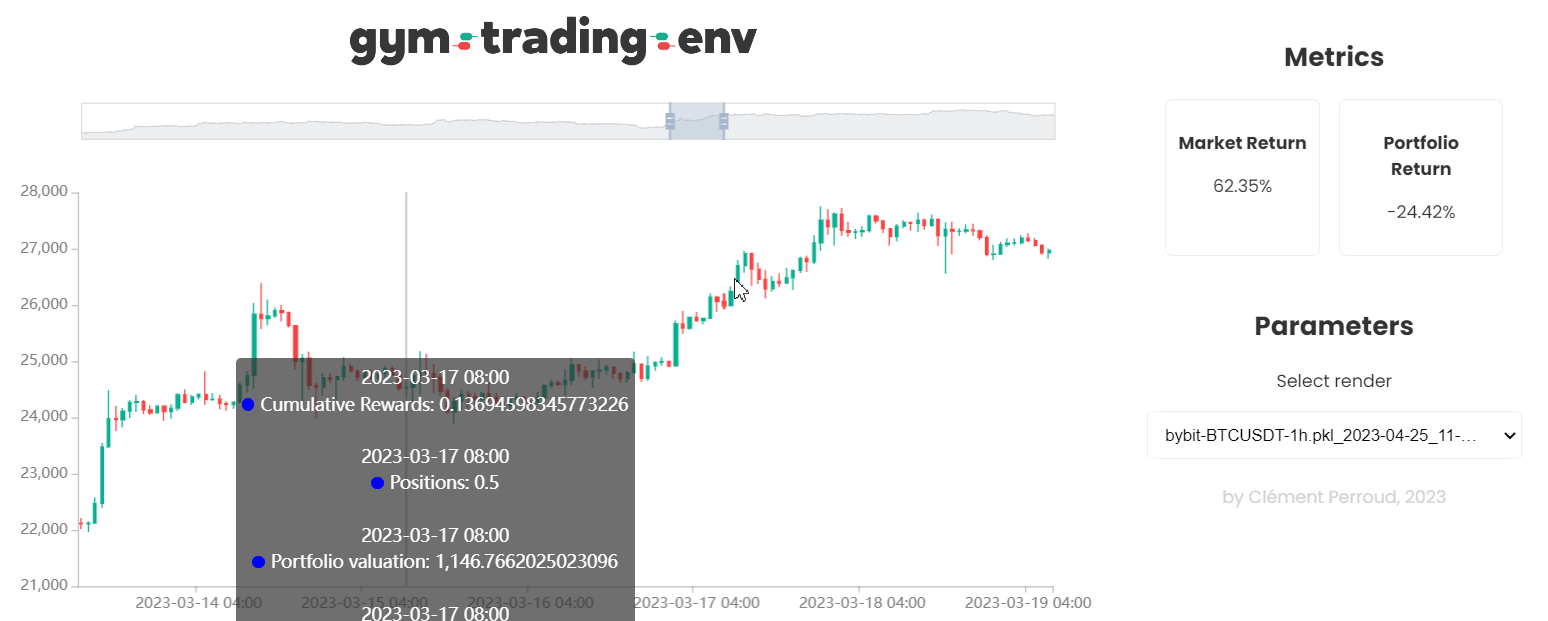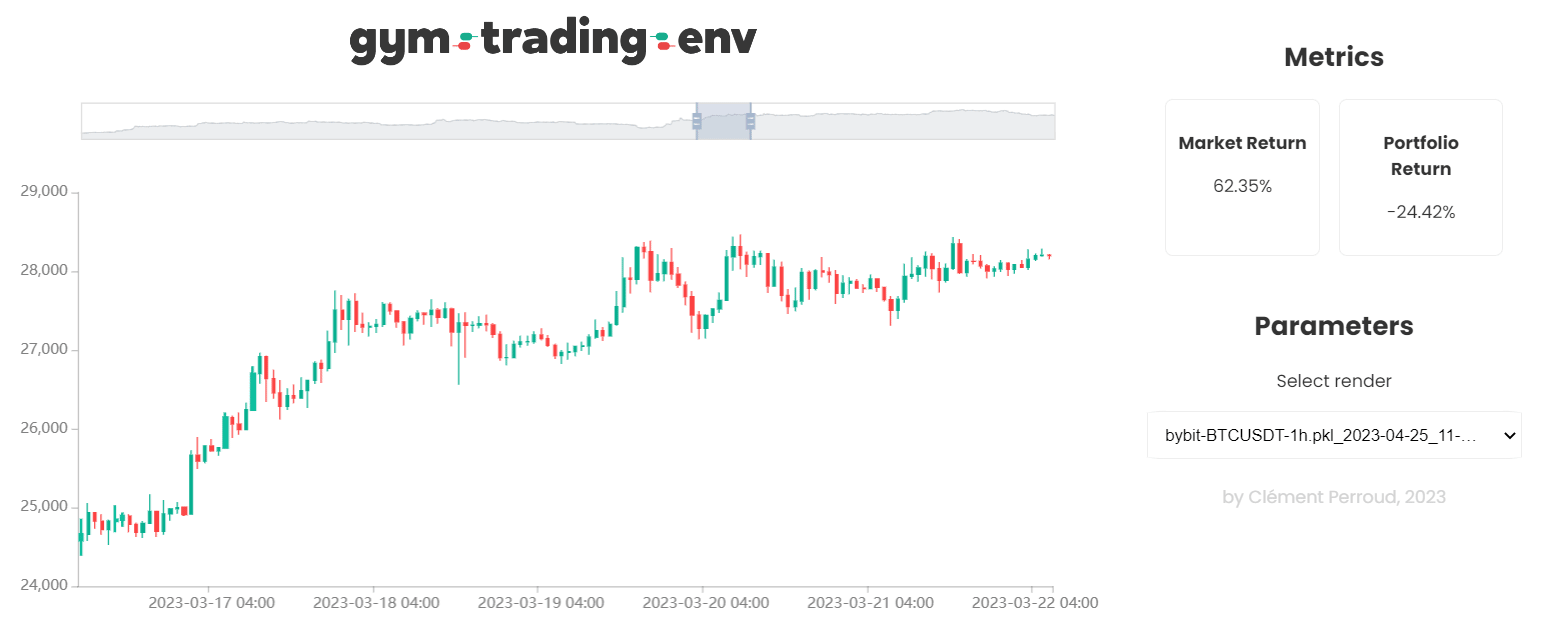
This environment is a Gymnasium environment designed for trading on a single pair.
Action Space |
|
Observation Space |
|
Import |
|
Important Parameters#
df(required): A pandas.DataFrame with acloseand DatetimeIndex as index. To perform a render, your DataFrame also needs to containopen,low, andhigh.positions(optional, default: [-1, 0, 1]): The list of positions that your agent can take. Each position is represented by a number (as described in the Action Space section).
Action Space#
The action space is a list of positions given by the user. Every position is labeled from -inf to +inf and corresponds to the ratio of the portfolio valuation engaged in the position ( > 0 to bet on the rise, < 0 to bet on the decrease).
Position examples |
BTC (%pv) |
USDT (%pv) |
Borrowed BTC (%pv) |
Borrowed USDT (%pv) |
|---|---|---|---|---|
0 |
100 |
|||
1 |
100 |
|||
0.5 |
50 |
50 |
||
2 |
200 |
100 |
||
-1 |
200 |
100 |
If position < 0: the environment performs a SHORT (by borrowing USDT and buying BTC with it).
If position > 1: the environment uses MARGIN trading (by borrowing BTC and selling it to get USDT).
Observation Space#
The observation space is an np.array containing:
The row of your DataFrame columns containing
featuresin their name, at a given step : the static featuresThe dynamic features (by default, the last position taken by the agent, and the current real position).
>>> df["feature_pct_change"] = df["close"].pct_change()
>>> df["feature_high"] = df["high"] / df["close"] - 1
>>> df["feature_low"] = df["low"] / df["close"] - 1
>>> df.dropna(inplace= True)
>>> env = gymnasium.make("TradingEnv", df = df, positions = [-1, 0, 1], initial_position= 1)
>>> observation, info = env.reset()
>>> observation
array([-2.2766300e-04, 1.0030895e+00, 9.9795288e-01, 1.0000000e+00], dtype=float32)
If the windows parameter is set to an integer W > 1, the observation is a stack of the last W states.
>>> env = gymnasium.make("TradingEnv", df = df, positions = [-1, 0, 1], initial_position= 1, windows = 3)
>>> observation, info = env.reset()
>>> observation
array([[-0.00231082, 1.0052915 , 0.9991996 , 1. ],
[ 0.01005705, 1.0078559 , 0.98854125, 1. ],
[-0.00408145, 1.0069852 , 0.99777853, 1. ]],
dtype=float32)
Reward#
The reward is given by the formula \(r_{t} = ln(\frac{p_{t}}{p_{t-1}})\text{ with }p_{t}\text{ = portofolio valuation at timestep }t\) . It is highly recommended to customize the reward function to your needs.
Starting State#
The environment explores the given DataFrame and starts at its beginning.
Episode Termination#
The episode finishes if:
1 - The environment reaches the end of the DataFrame, truncated is returned as True
2 - The portfolio valuation reaches 0 (or bellow). done is returned as True. It can happen when taking margin positions (>1 or <0).
Arguments#
- class gym_trading_env.environments.TradingEnv(df: ~pandas.core.frame.DataFrame, positions: list = [0, 1], dynamic_feature_functions=[<function dynamic_feature_last_position_taken>, <function dynamic_feature_real_position>], reward_function=<function basic_reward_function>, windows=None, trading_fees=0, borrow_interest_rate=0, portfolio_initial_value=1000, initial_position='random', max_episode_duration='max', verbose=1, name='Stock', render_mode='logs')#
An easy trading environment for OpenAI gym. It is recommended to use it this way :
import gymnasium as gym import gym_trading_env env = gym.make('TradingEnv', ...)
- Parameters
df (pandas.DataFrame) – The market DataFrame. It must contain ‘open’, ‘high’, ‘low’, ‘close’. Index must be DatetimeIndex. Your desired inputs need to contain ‘feature’ in their column name : this way, they will be returned as observation at each step.
positions (optional - list[int or float]) – List of the positions allowed by the environment.
dynamic_feature_functions (optional - list) –
The list of the dynamic features functions. By default, two dynamic features are added :
the last position taken by the agent.
the real position of the portfolio (that varies according to the price fluctuations)
reward_function (optional - function<History->float>) – Take the History object of the environment and must return a float.
windows (optional - None or int) – Default is None. If it is set to an int: N, every step observation will return the past N observations. It is recommended for Recurrent Neural Network based Agents.
trading_fees (optional - float) – Transaction trading fees (buy and sell operations). eg: 0.01 corresponds to 1% fees
borrow_interest_rate (optional - float) – Borrow interest rate per step (only when position < 0 or position > 1). eg: 0.01 corresponds to 1% borrow interest rate per STEP ; if your know that your borrow interest rate is 0.05% per day and that your timestep is 1 hour, you need to divide it by 24 -> 0.05/100/24.
portfolio_initial_value (float or int) – Initial valuation of the portfolio.
initial_position (optional - float or int) – You can specify the initial position of the environment or set it to ‘random’. It must contained in the list parameter ‘positions’.
max_episode_duration (optional - int or 'max') – If a integer value is used, each episode will be truncated after reaching the desired max duration in steps (by returning truncated as True). When using a max duration, each episode will start at a random starting point.
verbose (optional - int) – If 0, no log is outputted. If 1, the env send episode result logs.
name (optional - str) – The name of the environment (eg. ‘BTC/USDT’)